Jain, Murty and Flynn present a taxonomy of clustering techniques in their 1999 paper Data Clustering: A Review. The intention of the paper is to "survey the core concepts and techniques in the large subset of cluster analysis with its roots in statistics and decision theory" (p. 266).
In the introduction of the paper, the authors importantly define clustering as a means for unsupervised learning and discern this sciences' difference to supervised learning. Clustering facilitates the grouping of a given collection of unlabelled patterns into meaningful clusters (similar data points). This is accomplished through measuring proximity (similarity) between data points - through well defined algorithms. On the other hand, in supervised learning schemes the data set is already classified into labelled patterns. The problem is instead is to label a newly encountered.
The paper then moves onto identify and describe the principle components of a clustering task. These tasks can be separated into three primary steps and two additional if-needed type steps:
1. pattern representation: this step is concerned with the preprocesses of feature extraction and feature selection where the forma is the process of abstracting the most effective subset of the original data set to use in clustering while the latter relates to the use of transformation(s) of the original data set to produce a revised data set;
2. definition of a pattern proximity measure appropriate to the data domain e.g.
Euclidean distance;
3. clustering or grouping stage: this is the crux of unsupervised learning. Clusters can be either hard (definite partitions between groups) or alternatively fuzzy (where a pattern has varying degree of membership in each of the output clusters);
4. data abstraction: this step relates to the process of extracting simply and compact descriptions of clustered patterns;
5. assessment of output: this post-process aims to use specific measures of optimality to review the validity of clustering outcomes. Typically, statistical techniques and hypothesis type tests are employed to facilitate this process.
The authors then delve into the motivation for their paper, stating that previous critical analysis of clustering algorithms had failed to provide a framework for assessing tradeoffs of different techniques and for making a decision about which algorithm(s) to employ in a particular application. The authors make the observation that clustering algorithms contain implicit assumptions about the nature of the distribution of a data set. That is, the diversity of the clustering algorithms available to practitioners is a condition of the impossibly large number of possible unsupervised learning problems in existance. Hence with reference to their previously mentioned framework, the motivation for the paper.
Data Clustering: A Review is loosely organised by preprocesses, similarity measures, a taxonomy of clustering methods and techniques, and clustering applications.
Preprocesses: pattern representation, feature selection and extraction
This short section of the paper presents a number of observations about these preprocesses. With respect to pattern representation, it is noted that good representation can lead to simple and easily understood clustering i.e. polar coordinate versus Cartesian coordinates for a curvilinear cluster.
Similarity Measures
Similarity is the fundamental concept of unsupervised learning. In practice, it is dissimilarity between two patterns that is typically employed within learning schemes. Dissimilarity is measured by a distance measure defined on the feature space.
The most popular form of distance measurement for continuous features is the Euclidean distance (Minkowski metric). This technique's popularity centres about its intuitive appeal - it is used to calculate distance between objects in two and three-dimensional space.
This section of the paper reviews the Euclidean distance technique and introduces and similarly analyses a number of other similarity measures. These include distance based on counts for nominal attributes, syntatic approaches and mutual neighbour distance (MND).
A Taxonomy of Clustering Methods and Techniques
For the purpose of my project, this in-depth section of the paper is by far the most relevant.
The taxonomy describes the different approaches to data mining with a well-defined hierarchy. However, before traversing this hierarchy and each node's clustering algorithms the authors discuss five issues affecting different approaches regardless of their placement in the taxonomy:
1. Agglomerative ("bottom-up") versus divisive ("top-down"): the forma relates to algorithmic structure and operation that begins with each data point in a distinct cluster, and iteratively condenses these clusters until some stop condition is met. The latter on the other hand, begins with all data points in a single cluster and the iteration process stops splitting the clusters upon some stop-condition;
2. Monothetic versus polythetic: in the forma approach all features (axes) are included in calculating distances between patterns, whilst in the latter features are considered sequentially. Note that in the polythetic approac 2^d clusters are spawn;
3.
Hard versus
fuzzy: in a hard approach a data point is allocated a single cluster, whilst in a
fuzzy approach a data point is assigned degrees of membership in several clusters;
4. Deterministic versus stochastic: the forma approach sees optimization being sought through traditional techniques (well-defined) whilst the latter performs a random search of the state space consisting of all possible labelings; and
5. Incremental versus non-incremetal: incremental approaches to clustering are not concerned with minimizing scans through the data set while non-incremental are (more efficient approaches have emerged since larger data sets have emerged).
Now, onto the taxonomy.
A. Hierarchical Clustering Algorithms
Hierarchical clustering algorithms produce classifications that can be considered from multiple levels of abstraction. A dendrogram is a representation of this nested grouping.
i. Single-link algorithm: the distance between two clusters is the minimum distances between all pairs of data points drawn from the two clusters
ii. Complete-link algorithm: the distance between to clusters is the maximum of all pairwise distances between patterns in the two clusters.
Algorithm (i) has a tendency to produce elongated clusters (the chaining effect), whilst algorithm (ii) produces tightly bound clusters. This aside, (i) is overall thought to be versatile than (ii).
Three hierarchical clustering algorithms are then explained:
1. Agglomerative Single-Link Clustering Algorithm;
2. Agglomerative Complete-Link Clustering Algorithm; and
3. Hierarchical Agglomerative Clustering Algorithm.
B. Partitional Algorithms
Partitional clustering algorithms obtain single partitions of data sets instead of a clustering-type structure. They are robust in the sense that they are suitable for analysing large data sets, however the choice of the number of clusters may seem arbitrary.
These algorithms generally discover clusters by optimizing some criterion function. The most intuitive and frequently used partitional algorithm is the squared error criterion. The k-means is the simplest and most commonly used algorithm employing this criterion. This works by starting with some random initial partition and then iteratively reassigns data points to clusters "based on the similarity between the data point and the cluster centres until a convergence criterion is met" (p.278). This convergence criterion may be no reassignment of datapoints between clusters or a stable error term. Note worthy are the variations of the k-means algorithm. In particular, a robust form of this algorithm will see the splitting of clusters whose distance between data points in above some threshold and merge clusters whose distance is below this threshold.
Another type of partitional algorithm is graph-theoretic clustering. The best-known graph-theoretic clustering is based on the construction of the minimal spanning tree (MST) of the data, and then deleting the longest edges so as to form clusters.
The taxonomy then broadly introduces nearest neighbour clustering in which an unlabeled data point is assigned the cluster of its nearest labeled neighbour (within some distance bounds).
The next part of paper goes into representation of clusters, that is how the outcome of classification is infact summarised and communicated. Three representations were suggested:
1. Represent a cluster of data points by their centroid (when clusters are compact or isotropic) or by distant points in the cluster (when clusters are elongated or non-isotopic);
2. Represent clusters using nodes in a classification tree; and
3. Represent clusters by using conjunctive logical expressions.
The taxonomy arrives next at Artificial Neural Networks (ANNs) which are said to be massively parallel distributed networks of simple processing units i.e. neurons. ANNs are characterised by pertaining to only numeric vectors and which learn adaptively through shifting interconnecting semantic weights. Examples of ANNs include Kohonen's learning vector quantization (LVQ) and self-organising map (SOM).
The next group of algorithms introduced are evolutionary approaches to clustering. These algorithms employ the evolutionary operators of selection, recombination, and mutation in potential solution transformations. The best-known evolutionary techniques used in clustering are genetic algorithms (GAs), evolution strategies (ESs), and evolutionary programming (EP).
Some other unsupervised learning techniques brushed over include fuzzy clustering algorithms, mixture-resolving and mode-seeking algorithms as well as search-based approaches (like the branch-and-bound technique and clustering based on simulated annealing).
The taxonomy then moves into critical evaluation, providing a summary of previous studies comparing clustering techniques and their respective findings. The dimension of these comparisons largely relate to effectivenes (how good the clustering outcomes were), efficiency (the speed of the classification) and other data set related concerns (dimensionality, size and distribution). Various results were attained through testing and empirical studies. Obviously, some algorithms performed better than others.
The framework is further explored through a discussion of the subjective nature of clustering - every clustering algorithm uses some type of knowledge either implicitly or explicitly.
Large data set type problems are then addressed with the authors providing a description of the Incremental Clustering Algorithm as a suggested solution.
Four applications of data mining are then explored in great detail. This exploration process provides a vehicle for the discussion and critical analysis of a lot of the concepts introduced throughout the paper.
A summary ties together some of the loose ends of previous sections and reiterates some of the important aspects of clustering.

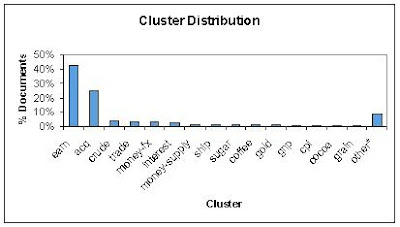
 The above table illustrates the nature of this corpus transformation. The emerging corpus has 9032 documents which pertain to 65 unique clusters.
The above table illustrates the nature of this corpus transformation. The emerging corpus has 9032 documents which pertain to 65 unique clusters.