Fuzzy Documents refers to the documents from the Reuters-21450 dataset which were assigned more than one label. Since I am undertaking non-fuzzy clustering experiments it is necessary to remove these types of documents from the dataset.
What am I left with?
What am I left with?
 The above table illustrates the nature of this corpus transformation. The emerging corpus has 9032 documents which pertain to 65 unique clusters.
The above table illustrates the nature of this corpus transformation. The emerging corpus has 9032 documents which pertain to 65 unique clusters.How are these clusters distributed?
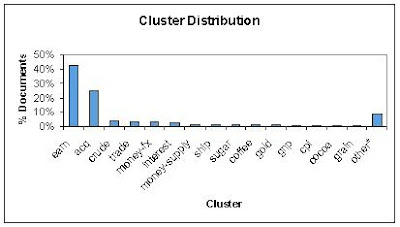
In the above chart, only clusters with greater than 50 documents are included. That is, clusters whose documents represent greater than 0.6% of the corpus. These are the 'top 15' documents, and in total they account for 91.4% of all documents. The rest are allocated to other: 774 documents. The 'top two' clusters represent 68% of all documents, and thus this dataset is not normally distributed.
No comments:
Post a Comment