KEA versus Carrot2
KEA stands for Keyphrase Extraction Algorithm and, as its name suggests, is used to extract keyphrases and words from text. It is a verbose system which allows for both controlled indexing and free indexing. The forma is concerned with extracting keyphrases from documents with reference to a controlled vocabulary providing for a more concept-based approach to extraction whilst the latter does not consider different term meaning e.g. lap-top will not be considered the same as note-book. These are natural language processing anomolies. KEA does not undertake clustering, but instead employs a supervised learning approach and builds a Baive Bayes learning model through a set of training documents with known keyphrases. For the purposes of training, phrase "term-frequency-inverse-document-frequency" (TF-IDF) weight as well as position within the document are considered. (El-Beltagy, 2006)
Carrot2 has been introduced previously. This scheme is very different to KEA, as it takes-on an unsupervised approach to text mining and phrase extraction. In terms of implementation however, there are many similarities in the initial stages of text mining. Consider the following:

The above diagram illustrates a summary of the information retrieval and document preprocessing implementation of text mining employed by both KEA and Carrot2 (however, with Carrot2 specifically geared for web search results). As eluded to on the post on September 2, Carrot2 explicitly uses Apache Lucene 2.2 (adjusted for web search resutls) to facilitate the above processes. Each broadly undertakes each of -> points depicted in the central box, except for the marked [] which relates to the KEA controlled indexing approach to text mining. The other marking within this box * ear-marks variation between the two text mining schemes and well as signing options within the individual schemes. Each is now considered:
1. Stemming: there are a number of implicit options available to both schemes with regards to stemming-
a. Lovins Stemmer: the most aggressive stemmer, with some 294 nested rules;
b. Porter Stemmer: this more subdued approach has some 37 rules;
c. Partial Porter Stemmer: the Porter Stemmer has 5 multi-part stages which allow the "miner" to be more or be less conservative in their stemming process. The first stage Porter stemmer is a popular methodology, handling basic plurals e.g. horses becomes horse, processes becomes process, men does not become man; and
d. No Stemmer.
2. Stop words: KEA defines some 499 stop-words, Carrot2 some 324 stop-words (adjusted lucene), lucene only some 33 and the Brown Corpus some 425 (Sharma et Raman, 2003).
3. Vocabularies: This is only relevant to KEA. The "miner" is able to dicate a dictionary, thesaurus or list of terms when undertaking controlled indexing. Also, in terms of implementation, these can be in either text form or resourse description format ("rdf"). A number of popular vocabularies are in circulation, including the integrated public servicevocabulary ("ipsv") and the agrovoc vocoabulary.
How do these options affect clustering?
There are essentially horses for courses. That is, a particular data set or text mining experiment may require more aggressive or more conservative preprocessing.
How do these systems relate to my thesis?
I am now working on the specific implementation of clustering: LSA/SVD & description comes first - replacing KEA's NaiveBayes classifier with Carrot2's lingo algorithm. These frameworks are both java based and open-source.
KEA provides a very suitable fit with my experiments, as it is not based on an index of Internet search results but instead a directory of text files. Carrot2's lingo is an unsupervised approach to learning and hence allows for clustering. A potential shortfall of this approach is that lingo uses LSA/SVD and hence forms a term-document matrix- thus unsuitable for scalability considering the size of my proposed Reuters-21450 dataset (see also post relating to pre-preprocssing of this dataset). I have a number of papers which focus on such constraints (i.e. using smaller term dictionaries, more aggressive stemming [as eluded to above], retricting the number of identified phrases - either by increasing minimum phrase length or increasing maximum phrase length, etc). This leads to, adapting Carrot2 for the purposes of larger datasets.
What are the limitations of such an approach?
Initial complexities associated with such an approach:
1. The purpose of Lingo2 is to create more understandable cluster labels, thus a tension exists between label quality (as well as associated cluster quality in description comes first) and scalability;
2. Even with very aggressive stemming, scalability may still be an issue -that is, the size of the dataset too large for such experiments. I could therefore reduce the number of concepts and associated documents.
Alternatively, I could adopt a different dataset. In so much I could undertake similar experiments to those reported on the KEA website. In these experiments, the group use the controlled agrovac vocabulary to extract key phrases from agricultural documents. I could extract phrases using the unsupervised KEA algorithm and compare the keyphrases as extracted using the adapted carrot2 scheme. That is, using the same extraction and preprocessing techniques and allowing for different clustering and resultant keyphrase extraction outcomes; and
3. Measuring cluster label quality and associated cluster quality - I have undertaking further research into this issue beyond my previous research.

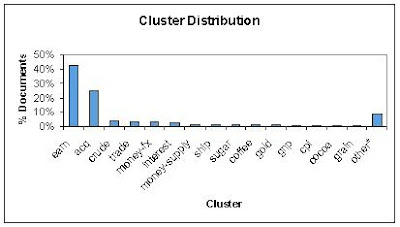
 The above table illustrates the nature of this corpus transformation. The emerging corpus has 9032 documents which pertain to 65 unique clusters.
The above table illustrates the nature of this corpus transformation. The emerging corpus has 9032 documents which pertain to 65 unique clusters.